고정 헤더 영역
상세 컨텐츠
본문
이 글은 힙 정렬(heap sort), 힙 소트 라고 불리는 정렬 알고리즘을 다룬다.
누구나 한번쯤은 들어봤고, 구현해본 정렬 중 하나이다.
빠른 정렬에 분류되고, 시간복잡도가 같은 퀵정렬과 합병정렬과 함께 언급된다.
퀵정렬 - http://mygumi.tistory.com/308
1. 힙 정렬이란 무엇인가?
2. 힙 정렬은 어떻게 구현하는가?
3. 힙 정렬은 어디에서 사용하는가?
힙 정렬은 완전 이진 트리를 기본으로 하는 힙(Heap) 자료구조를 기반으로한 정렬 방식이다.
완전 이진 트리는 삽입할 때 왼쪽부터 차례대로 추가하는 이진 트리를 말한다.
힙에는 부모 노드의 값이 자식 노드의 값보다 항상 큰 최대 힙과 그 반대인 최소 힙이 존재한다. (힙 위키)
주의할 점은 부모-자식 관계간의 이야기이고, 형제간은 고려하지 않는다.
시간복잡도는 최악, 최선, 평균 모두 O(nlogn) 을 가진다.
또한 불안정 정렬에 속한다. (불안정 정렬의 의미를 모른다면 참고글)
1. 최대 힙을 구성한다.
2. 현재 힙의 루트는 가장 큰 값이 존재하게 된다. 루트의 값을 마지막 요소와 바꾼 후, 힙의 사이즈를 하나 줄인다.
3. 힙의 사이즈가 1보다 크면 위 과정을 반복한다.
위 과정은 사실상 힙 자체의 연산 중에서 extract 연산을 이용한다.
extract 연산은 힙으로부터 루트를 삭제하고, 다시 힙을 구성하는 절차이다.
그림으로 표현하면 다음과 같다. (자세한 내용은 위에서 링크한 영문으로된 위키를 참고바란다)

위와 같이 힙에서 루트를 마지막 노드로 대체하는 모습을 보여주고 있다.
그 후, 다시 최대 힙을 구성하는 모습은 아래와 같다.
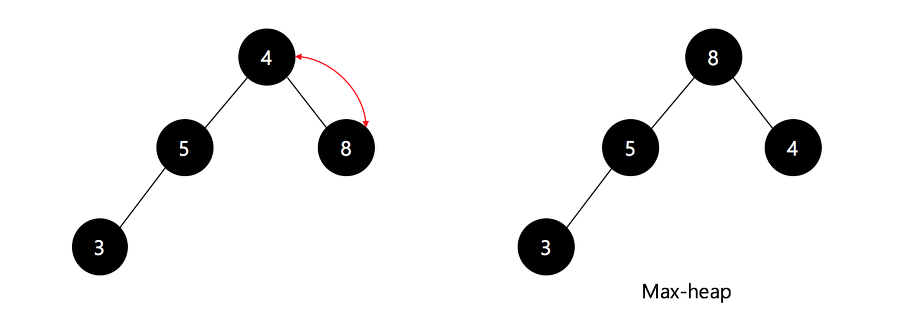
위와 같은 방식으로 최대 값을 하나씩 뽑아내면서 정렬을 할 수 있게 된다.
이것이 가능한 이유는 최대 힙을 구성한다는 것이 루트에 가장 큰 값이 존재한다는 의미가 되기 때문이다.
힙을 이해한다면, 쉽게 힙 정렬을 이해할 수 있다.
위 흐름의 전체 코드는 다음과 같다.
public void heapSort(int[] array) { int n = array.length; // init, max heap for (int i = n / 2 - 1; i >= 0; i--) { heapify(array, n, i); // 1번 } // for extract max element from heap for (int i = n - 1; i > 0; i--) { swap(array, 0, i); // 2번 heapify(array, i, 0); // 1번 } }
첫번째 heapify() 는 단순히 일반 배열을 힙으로 구성하는 역할을 한다.
그 과정에서 자식 노드로부터 부모 노드를 비교한다.
n / 2 - 1 부터 0까지는 인덱스가 도는 이유는 부모 노드의 인덱스를 기준으로 왼쪽자식노드(i * 2 + 1), 오른쪽자식노드(i * 2 + 2) 이기 때문이다.
두번째 heapify() 는 요소가 하나 제거된 후 다시 최대 힙을 구성하기 위함이다.
extract 연산과 같은 처리를 하기 위해 루트를 기준으로 진행된다.
heapify() 의 내부는 다음과 같다.
public void heapify(int array[], int n, int i) { int p = i; int l = i * 2 + 1; int r = i * 2 + 2; // left childNode if (l < n && array[p] < array[l]) { p = l; } // right childNode if (r < n && array[p] < array[r]) { p = r; } // parentNode < childNode if (i != p) { swap(array, p, i); heapify(array, n, p); } }
코드는 다시 최대 힙을 구성할때까지 부모 노드와 자식 노드를 스왑하면서 재귀적으로 진행된다.
일반적으로 힙 자료구조는 힙 정렬과 함께 언급된다.
사실상 대부분의 경우 퀵정렬 또는 합병정렬의 성능이 좋기 때문에 힙 정렬의 사용빈도는 높지않다.
그렇다고 힙 자료구조 자체의 사용빈도를 말하는 것은 아니다.
힙 자료구조는 많이 사용되고, 많은 알고리즘과 연관되어있다.
다음은 힙 정렬에 유용한 예가 된다.
1. 가장 크거나 작은 값을 구할 때
2. 최대 k 만큼 떨어진 요소들을 정렬할 때
1번의 경우는 최소 힙 또는 최대 힙의 루트 값이기 때문에 한번의 힙 구성을 통해 쉽게 구할 수 있다.
2번의 경우에는 일반적으로 삽입정렬을 활용할 수 있지만, 힙 정렬을 통해서 더욱 개선할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
private void solve() {
int[] array = { 230, 10, 60, 550, 40, 220, 20 };
heapSort(array);
for (int v : array) {
System.out.println(v);
}
}
public static void heapify(int array[], int n, int i) {
int p = i;
int l = i * 2 + 1;
int r = i * 2 + 2;
if (l < n && array[p] < array[l]) {
p = l;
}
if (r < n && array[p] < array[r]) {
p = r;
}
if (i != p) {
swap(array, p, i);
heapify(array, n, p);
}
}
public static void heapSort(int[] array) {
int n = array.length;
// init, max heap
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(array, n, i);
}
// for extract max element from heap
for (int i = n - 1; i > 0; i--) {
swap(array, 0, i);
heapify(array, i, 0);
}
}
public static void swap(int[] array, int a, int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}
|
cs |
출처: https://mygumi.tistory.com/310?msclkid=85c0acf0a78e11ecab83412b125df89e [마이구미의 HelloWorld]
'Study > Algorithm' 카테고리의 다른 글
| 플로이드 와샬 알고리즘 (0) | 2022.03.19 |
|---|---|
| 합병정렬(merge sort) (0) | 2022.03.19 |
| DFS (깊이 우선 탐색) (0) | 2022.03.19 |
| BFS (너비 우선 검색) 정리 (0) | 2022.03.19 |
| 분할정복(Divide and Conquer) (0) | 2022.03.19 |




